Abstract
We introduce pix2gestalt, a framework for zero-shot amodal segmentation, which learns to estimate the shape and appearance of whole objects that are only partially visible behind occlusions. By capitalizing on large-scale diffusion models and transferring their representations to this task, we learn a conditional diffusion model for reconstructing whole objects in challenging zero-shot cases, including examples that break natural and physical priors, such as art. As training data, we use a synthetically curated dataset containing occluded objects paired with their whole counterparts. Experiments show that our approach outperforms supervised baselines on established benchmarks. Our model can furthermore be used to significantly improve the performance of existing object recognition and 3D reconstruction methods in the presence of occlusions.
Zero-shot Amodal Perception
We demonstrate pix2gestalt's zero-shot amodal completion & segmentation capability on occlusions ranging from natural images to post-impressonist art. Please click on the videos to visualize our amodal reconstructions.
Natural Images (Amodal COCO)
We show qualitative results on Amodal COCO.
Natural Images (Amodal BSDS)
We show qualitative results on Amodal Berkeley Segmentation Dataset.
Visual Art
Occlusions in visual art often challenge priors on the natural image manifold. We showcase examples ranging from surrealist paintings to black & white photographs.
Negative Space Occlusions
While occluders are often elements of positive space, they can function as negative space too. Such cases challenge physical priors. We show negative space occlusions within sculptures, Magritte’s paintings, and one created by Harry Potter’s invisibility cloak.
Physical States within Occlusions
pix2gestalt can often uncover physical states of the world plausible within occlusions. In these examples, water accumulating on the tooth brush and the baby's weight marks on the sofa are captured.
Optical Illusions
While older methods can solve the checker-shadow illusion too, we sanity check whether our method can de-occlude its checkerboard with correct texture.
Practical Settings
Amodal perception is crucial for many downstream applications in vision, graphics, and robotics. We show practical examples from robotics and autonomous driving.
Limitations
We found that our approach has limitations in situations that require commonsense or physical reasoning. Notice the car going in the wrong direction, or the following samples that contradict physics.
How does it work?
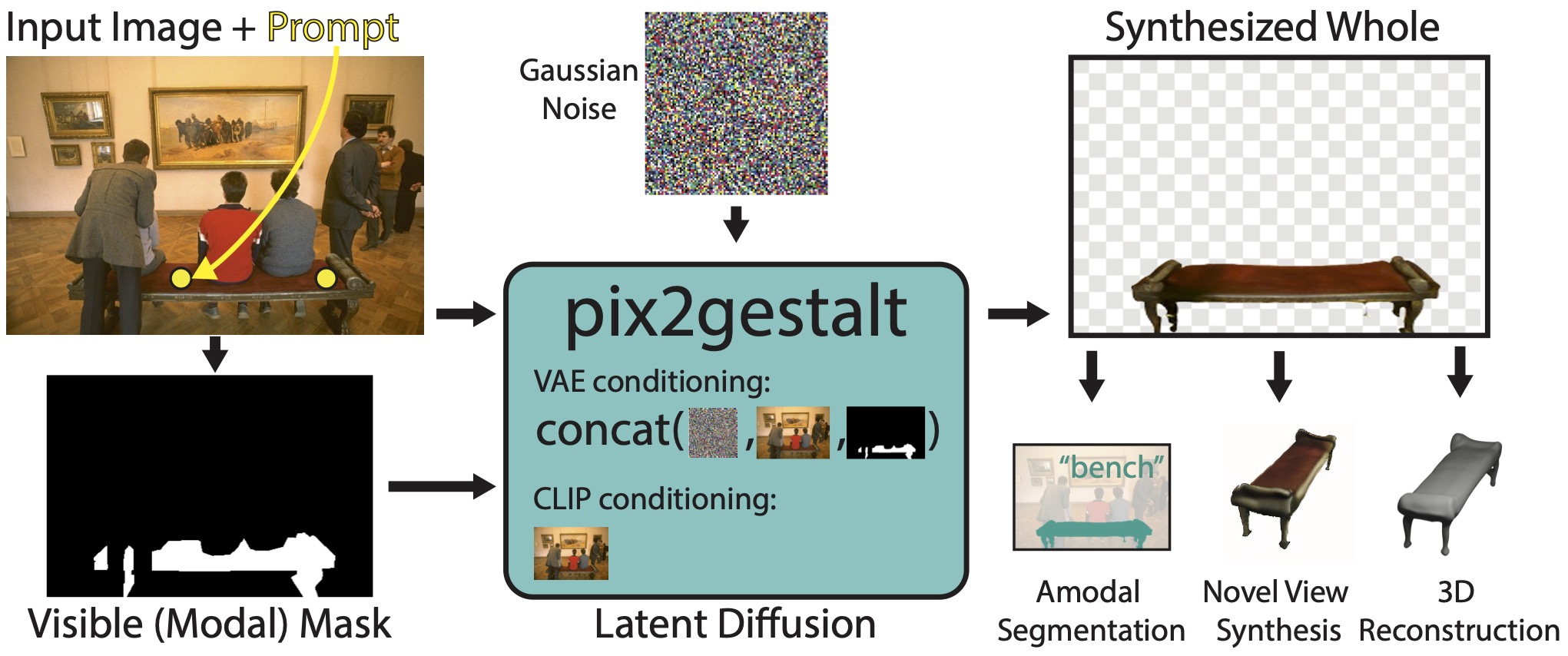
We propose an amodal completion model using a latent diffusion architecture. Conditioned on an input occlusion image and a region of interest, the whole (amodal) form is synthesized, thereby allowing other visual tasks to be performed on it too. For conditioning details, see section 3.2 of our paper.
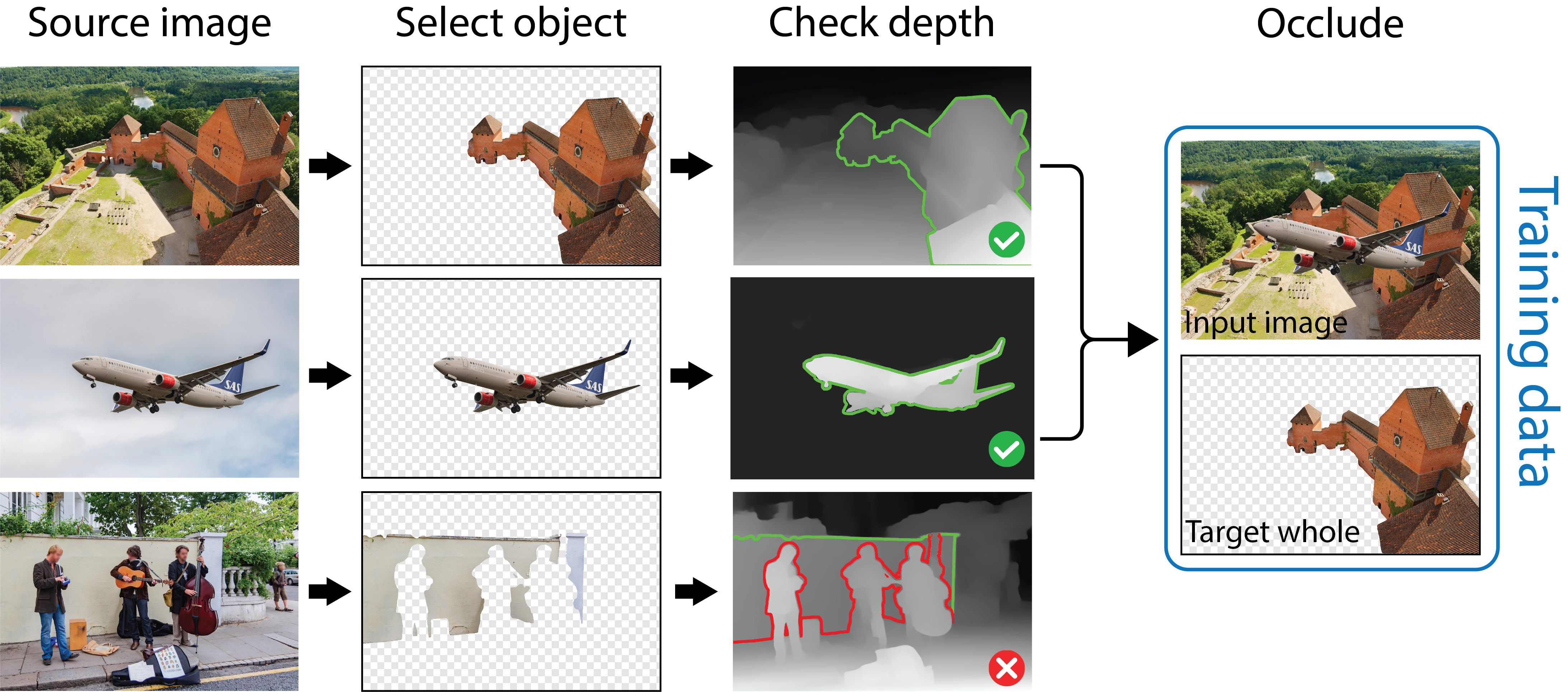
As training data, we use a synthetically curated dataset containing occluded objects paired with their whole counterparts. To ensure we only occlude whole objects, we use a heuristic that objects closer to the camera than its neighbors are likely fully visible.The green outline around the object shows where the estimated depth is closer to the camera than the background (the red shows when it is not).
Concurrent Work
BibTeX
@article{ozguroglu2024pix2gestalt,
title={pix2gestalt: Amodal Segmentation by Synthesizing Wholes},
author={Ege Ozguroglu and Ruoshi Liu and D\'idac Sur\'s and Dian Chen and Achal Dave and Pavel Tokmakov and Carl Vondrick},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}